Oder: was wir von den alten Griechen über den Umgang mit Technologie lernen können

Im Zeitalter fortschreitender Künstlicher Intelligenz und ihrem massiven Einfluss auf die Kreativbranche stellt sich bei unseren Kunden immer wieder die Frage, ob es sich überhaupt noch lohnt, eine/n professionellen Synchronsprecher/in zu buchen. Schließlich kann eine KI doch mittlerweile Stimmen perfekt imitieren, oder? Werden in Zukunft nicht sowieso alle Filme nur noch künstlich generiert, inklusive epischem Orchesterscore, Soundeffects und simultane Verfügbarkeit in 248 Sprachen?
Sobald man sich dem Thema nähert, ploppen auf einmal viele Fragen auf. Verunsicherung macht sich breit. Aber wie funktioniert eigentlich die künstliche Stimmerzeugung? Wo liegen ihre Vor- und Nachteile? Und, viel wichtiger:
Müssen Synchronsprecher und andere Künstler tatsächlich um ihren Job fürchten?
Künstliche Stimmen sind nicht neu
Eine Sache vorweg: Synthetische Stimmen, heute oft einfach nur “KI-Stimmen” genannt, sind nicht wirklich so neu, wie man denkt. Nur: Heute sind sie allgegenwärtig. Und dank der rasant fortschreitenden Entwicklung der Technologiebranche klingen künstliche Stimmen mittlerweile annähernd wie menschliche.
Die Forschung an künstlich erzeugten Stimmen, auch als Sprachsynthese oder Text-to-Speech (TTS) bezeichnet, hat eine lange Geschichte: Die ersten Versuche reichen bis in die 1940er Jahre zurück1. Forscher begannen schon damals, Sprachmodelle zu entwickeln, die Laute und Silben generieren konnten.
Hier ist z.B. der sogenannte „Voder“ von Homer Dudley zu sehen. Dieser wurde 1939 auf der Weltausstellung in New York vorgeführt:
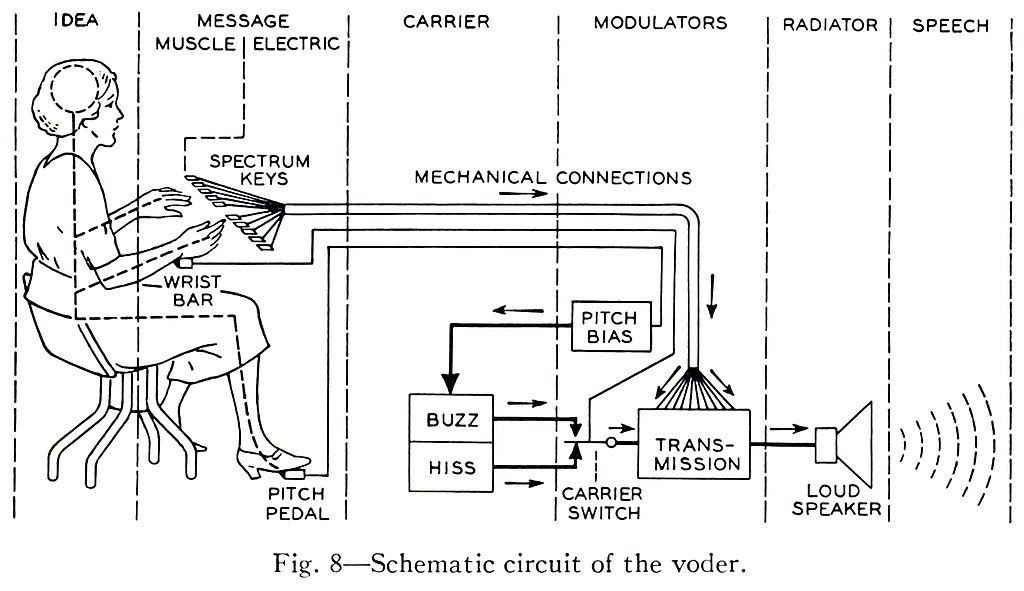
Und so klang der Voder von Homer Dudley:
In den 1960er und 1970er Jahren wurden mit Fortschritten in der Computertechnologie die ersten TTS-Systeme entwickelt, die einfache Sätze synthetisieren konnten. Diese waren jedoch noch sehr begrenzt und klangen oft roboterhaft und unnatürlich.
In den 1980er und 1990er Jahren schließlich führten weitere Fortschritte in der Computerleistung und in der Spracherkennungstechnologie zu einer deutlichen Verbesserung der Qualität der TTS-Systeme. Diese Systeme konnten nun flüssigere und natürlichere Sprache synthetisieren und wurden in einer Vielzahl von Anwendungen eingesetzt, z. B. in Sprachausgabegeräten für Menschen mit Behinderungen, in Telefon-Navigationssystemen und in Sprachantworten.

In den letzten Jahren haben nun neuronale Netze die TTS-Technologie revolutioniert. Diese Systeme können aus riesigen Datensätzen lernen und erzeugen synthetische Sprache, die von der menschlichen kaum zu unterscheiden ist.
Nicht nur Synchronsprecher machen sich daher Sorgen um ihren Job – auch Politik und Wirtschaft versuchen, mit der technischen Entwicklung Schritt zu halten: Denn dieser rasante technologische Fortschritt öffnet natürlich auch Türen für Betrug und Manipulation.
Das Versprechen der großen Konzerne und Forscher jedoch ist klar: KI soll dem Menschen zu neuen Höchstleistungen verhelfen, ihn effizienter machen, seine Produktivität steigern, Krankheiten früher erkennen und noch viel mehr. Das klingt ja alles prima. Aber ist es das auch?
Was haben jetzt die alten Griechen damit zu tun?
Kennt ihr die Geschichte der Pandora? Pandora war eine wunderschöne Frau, die von Hephaistos (Gott des Feuers) auf Zeus’ Auftrag hin aus Lehm geformt und zum Leben erweckt worden war. Zeus wollte sich mit ihrer Hilfe an Prometheus rächen, der den Göttern das Feuer stahl und es den Menschen überreichte.
Pandoras Aufgabe war es nun, dank ihrer Schönheit die Menschen in Versuchung zu bringen und ins Unheil zu stürzen. Daher wurde sie von den Göttern mit einigen weiteren nützlichen Eigenschaften ausgestattet, wie Geschicklichkeit und Verlogenheit. Mit sich trug Pandora die weltweit bekannte und zum Sprichwort gewordene “Büchse Der Pandora”. Diese Büchse enthielt alles Übel der Welt.

Allen gut gemeinten Ratschlägen zum Trotz empfing Epimetheus, Prometheus´ Bruder, die schöne Pandora und nahm sie zur Frau. Die beiden lebten zunächst unbeschwert und glücklich zusammen, doch im Laufe der Zeit vergaß auch Pandora ihre Vorsicht und öffnete die Büchse. Alles darin enthaltene Übel ergoss sich auf die Menschheit – bis auf die Hoffnung/Vorfreude (je nach Übersetzung). Sie blieb in der Büchse und ermöglichte es den Menschen, das Schlechte zu ertragen, da sie selbst an ihrer Situation arbeiteten, ohne auf bessere Zeiten zu hoffen.
Was heisst das jetzt für uns?
Wie wir gleich sehen werden, lässt sich das Gleichnis ganz gut auf das “Geschenk” der fortschreitenden Technik, wie künstliche Intelligenz anwenden.
In unserem Fall ist nämlich die künstliche Intelligenz ein bisschen wie Pandora. Einerseits ein verheißungsvolles Geschenk, mindestens aber eine Verführung, eventuell die Wurzel allen Übels, vielleicht aber auch der Schlüssel zum Glück. Auf jeden Fall muss man das Thema aus vielen Blickwinkeln betrachten und analysieren, bevor man sich ein Urteil verschafft.
„Technologie kann Großartiges vollbringen, aber sie will das nicht von sich aus. Sie will weder Gutes noch Böses tun.“
– Tim Cook, CEO Apple
Technologie an sich ist weder gut, noch böse. Es ist der Benutzer, der über den Zweck entscheidet.
KI-Stimmen vs Profi-Sprecher
Ich möchte Euch anhand dieses Artikels das Spannungsfeld KI-Stimmen vs. Sprecher näher bringen. Wir werden die grundsätzlichen Funktionen von verschiedenen Spracherzeugungs-Technologien behandeln, den Job eines Voice Over Artists beleuchten und die gegenseitigen Vor- und Nachteile besprechen.
- Wie funktionieren KI Stimmen eigentlich?
- Wie arbeiten dagegen menschliche Sprecher?
- Was sind die Vor- und Nachteile von echten Sprechern, bzw. von künstlichen Stimmen?
- Synchronsprecher vs. KI: Fazit
WICHTIG: Wir behandeln dieses Thema aus professioneller Sicht. Das heißt für die Produktion von professionellen Inhalten, die höchsten Ansprüchen genügen muss.
Wie funktionieren KI-Stimmen eigentlich?
Es gibt nicht den EINEN Ansatz für sogenannte „KI-Stimmen“ und trotz Ihrer umgangssprachlichen Bezeichnung werden sie nicht immer von echter KI produziert. Vielmehr werden oft unterschiedliche Technologien, oder sogar eine Kombination aus diesen verwendet. Diese reichen von relativ “einfachen” und größtenteils manuellen Verfahren, bis hin zu komplexen neuronalen Netzen. Ich möchte hier der Einfachheit halber nur die drei wichtigsten Methoden behandeln.
Die Verfahren, die heutzutage am häufigsten verwendet werden, sind:
- Concatenative Speech Synthesis (CSS)2,
- Generative Adversarial Networks (GAN)3 und
- Voice Cloning (VC)
Klingt erstmal ziemlich fancy und kompliziert. Ist es aber eigentlich gar nicht. Daher möchte ich im Folgenden kurz die groben Funktionsweisen dieser Systeme erläutern und gegenüberstellen. Ich will versuchen, alles so einfach wie möglich zu halten.
Concatenative Speech Synthesis (CSS)
Bei der “Concatenative Speech Synthesis” oder auf Deutsch “Konkatenative Sprachsynthese” werden – vereinfacht gesagt – kleine Segmente von Wörtern oder Sätzen (Silben, Phoneme, Diphone etc.) in hoher Qualität aufgenommen und aneinandergehängt (“Konkatenation” = Verkettung von Zeichen oder Zeichenketten).

Während der Sprachaufnahme werden unzählige Samples eines Sprechers in verschiedenen Betonungen und Tonalitäten aufgenommen. Diese Aufnahmen werden in der Postproduktion oft noch einmal nachbearbeitet: Es werden evtl. Störgeräusche entfernt, Tonlagen angepasst und die Segmentierung vorgenommen. Später werden diese Segmente dann mit Metadaten näher beschrieben. Zu diesen Metadaten gehören:
- Betonung des Sprechers
- Position des Segments innerhalb eines Wortes
- Sprecher-ID
- Segmenttyp (Wort, Silbe, Phonem ö.a.)
- Tonlage, und vieles mehr
Diese optimierten Segmente werden nun in einer Datenbank gespeichert. Auf diese Datenbank greift der Synthese-Algorithmus bei der Sprachausgabe anschließend zurück.

Generative Adversarial Networks (GAN)
Einen gänzlich anderen Ansatz als die CSS verfolgen Generative Adversarial Networks (GAN). GANs finden in vielerlei kreativen Bereichen Anwendung, z.B. bei der Bild- und Musikerzeugung, aber auch im Audiobereich. Im Prinzip stehen sich bei diesem Verfahren zwei neuronale Netze gegenüber: Ein Generator und ein Diskriminator.
Der Generator generiert zufällige, künstliche Ausgaben – in unserem Fall Sprachsamples. Der Diskriminator wiederum vergleicht diese Ausgaben mit echten Dateien. Er versucht während dieses Vorgangs, die echten von den synthetischen Dateien zu unterscheiden. Durch diesen “Wettbewerb” lernt der Generator, immer bessere Sprachausgaben zu erstellen und der Diskriminator lernt, Fakes besser zu erkennen.

Voice Cloning
Voice Cloning ist wohl das umstrittenste Verfahren. Nicht zuletzt wegen der zunehmenden Deep Fakes in Politik, Gesellschaft und Medien. Aber auch in unserer Branche gibt es viele Vorbehalte gegen diese Technologie.
Das Prinzip hinter diesem Verfahren steckt schon im Namen: Beim Voice Cloning werden Stimmen geklont. Das heißt, eine Stimme wird analysiert und danach manipuliert. Wir wollen dieses Verfahren hier einmal in 5 Schritte aufteilen:
- Datensammlung: Zunächst werden Sprachaufnahmen der Zielperson benötigt. Je umfangreicher und vielfältiger dieses Datenmaterial ist, desto besser wird die spätere Qualität des Klons.
- Datenaufbereitung: Die Sprachaufnahmen werden dann in einzelne Bestandteile zerlegt und analysiert. Dabei werden Faktoren wie Tonhöhe, Geschwindigkeit, Betonung und Klangfarbe untersucht.
- Training des neuronalen Netzes: Mit den aufbereiteten Daten wird ein neuronales Netzwerk – quasi das Gehirn der KI – trainiert. Dieses Netzwerk lernt die charakteristischen Merkmale der Stimme zu erkennen und miteinander zu verknüpfen.
- Sprachsynthese: Nachdem das neuronale Netz trainiert ist, kann es nun Text in Sprache umwandeln, die der Zielperson täuschend ähnlich klingt.
- Nachbearbeitung: Manchmal wird die synthetisierte Sprache noch einmal nachbearbeitet, um die Qualität und Natürlichkeit weiter zu verbessern.
Wir kennen jetzt also die Grundzüge der künstlichen Stimmerzeugung. Kommen wir nun zur Arbeitsweise menschlicher Sprecher und Sprecherinnen.
Wie arbeiten professionelle Sprecher?
Bevor wir uns mit der genauen Arbeitsweise eines Profi-Sprechers befassen, ein Gedanke vorweg:
Ich habe mich in den letzten 10 Jahren als professioneller Tonmeister viel mit der Bedeutung des Berufs, bzw. des Begriffes “Sprecher” auseinandergesetzt – vor allem im Anblick der immer schnelleren technologischen Entwicklung. Mein bisheriger Ansatz für eine Definition lautete:
„Ein Sprecher ist eine Person, die sich der Sprache bedient, um Informationen und/oder Emotionen zu vermitteln.“
Meiner Meinung nach ist es heutzutage notwendig, den Begriff etwas auszuweiten:
„Ein Sprecher ist eine Person oder ein System, die bzw. das sich der Sprache bedient, um Informationen und/oder Emotionen zu vermitteln.“
Auf die Gründe für diese Aussage wird am Ende dieses Artikels, im Fazit, eingegangen.
Aber nun zurück zum Thema:
Der Beruf eines professionellen (Synchron-) Sprechers

Der Beruf eines Synchronsprechers ist es, wie oben beschrieben Informationen und/oder Emotionen zu vermitteln. Dafür lernt er (oder sie) im Laufe seiner Ausbildung:
Stimmbildung:
- Atmung: Erlernen einer effizienten Atemtechnik, um die Stimme zu stützen und eine ausreichende Luftversorgung zu gewährleisten.
- Klang: Übungen zur Verbesserung von Tonumfang, Resonanz und Modulation der Stimme.
- Artikulation: Deutliche Aussprache und Betonung von Wörtern und Sätzen.
- Stimmhygiene: Vermeidung von stimmlichen Belastungen und Erkältungen.
Sprechtechnik:
- Textverständnis: Analyse und Interpretation von Texten, um die Intention des Autors zu erfassen.
- Textgestaltung: Betonung, Pausensetzung und Tempo, um den Text lebendig und verständlich zu gestalten.
- Mikrofontechnik: Umgang mit Mikrofonen und Aufnahmegeräten.
- Präsentationstechnik: Körpersprache und Mimik zur Unterstützung der gesprochenen Sprache.
Schauspiel:
- Improvisation: Übungen zur Spontanität und Kreativität.
- Rollenarbeit: Verkörperung verschiedener Charaktere und Emotionen.
- Hörspieltraining: Sprechen in verschiedenen Rollen und Situationen.
Zusätzlich zu diesen Kernbereichen kann eine Sprecherausbildung auch weitere Inhalte wie Rhetorik, Moderation, Synchronisation und Hörbuchsprechen umfassen.
Die meisten Sprecher haben vor ihrer Karriere eine Schauspielausbildung gemacht. Es gibt jedoch viele Möglichkeiten, Sprecher zu werden. Darunter zählen persönliche Voice Coachings, Selbststudium, aber auch Seminare und sogar Bachelor-Studiengänge.
Fertig ausgebildete Sprecher arbeiten später beim Hörfunk, bei Fernsehsendern, Verlagen oder – und das ist meistens der Fall – freiberuflich. Abseits der Unterhaltungsbranche finden sich jedoch auch diverse andere – oft recht exotische – Betätigungsfelder, so z.B. in der Politik, oder als Trauerredner.
Ein Tag im Leben eines professionellen Sprechers
Zu den täglichen Arbeiten eines professionellen Voice-Over Artists gehören:
Vorbereitung
- Textstudium: Analyse und Interpretation von Texten, um die Intention des Autors zu erfassen.
- Recherche: Hintergrundinformationen zum Thema sammeln und verstehen.
- Markierung des Textes: Betonung, Pausensetzung und Tempo festlegen.
- Üben: Den Text mehrmals laut vorlesen, um die Sprechgeschwindigkeit und die Betonung zu perfektionieren.
Aufnahme
- Pünktlichkeit und Zuverlässigkeit: Pünktliches Erscheinen im Tonstudio und professionelle Arbeitsweise.
- Zusammenarbeit mit dem Tonmeister: Anweisungen des Tonmeisters befolgen und Feedback geben.
- Konzentration und Ausdauer: Den Text fehlerfrei und mit der richtigen Betonung einsprechen.
- Umgang mit Lampenfieber: Nervosität überwinden und professionell performen.
Nachbereitung
- Abhören der Aufnahme: Sich selbst kritisch beurteilen und Verbesserungsvorschläge machen.
- Korrekturen: Fehler in der Aufnahme korrigieren.
Zusätzlich (als Freiberufler)
- Buchhaltung
- Weiterbildung
- Marketing
- Social Media

Sprecher zu sein bedeutet also im Prinzip, Kreativität, Feingefühl und Handwerk miteinander zu kombinieren. Es bedarf langjähriger Übung, Geduld und Erfahrung, um Inhalte überzeugend zu vermitteln.
Vor- und Nachteile von KI-Stimmen
Vorteile von KI-Stimmen
- Effizienz: KI-Stimmen können Text in Sekundenschnelle in Audio umwandeln. Dies spart Zeit und Geld bei der Aufnahme.
- Kostengünstig: KI-Stimmen sind häufig günstiger als professionelle Sprecher.
- Sprach-Flexibilität: Durch GAN oder VC erzeugte Stimmen können in hunderten verschiedenen Sprachen kommunizieren.
- Kontinuierliche Verbesserung (GAN): Durch den Wettstreit zwischen Generator und Diskriminator verbessern sich GANs kontinuierlich.
- Erzeugung neuer Stimmen: GANs können neue Stimmen generieren, die es in der realen Welt nicht gibt.
Nachteile von KI-Stimmen
- Aufwendigkeit: Das Trainieren einer KI, bzw. das Erzeugen einer Datenbank für CSS oder VC ist sehr aufwändig und zeitintensiv. Daher kann es für professionelle Ergebnisse auch schnell teuer werden.
- Zentralisierung: Man muss auf externe Anbieter zurückgreifen – dadurch gibt man auch wieder ein Stück Kontrolle an Externe ab.
- Mangelnde Flexibilität im Ausdruck: Keine KI der Welt ist bisher in der Lage, alle Nuancen des menschlichen Ausdrucks so abzubilden, wie es ein menschlicher Sprecher schafft.
- Emotionalität: Subtile Emotionen sind mit einer KI bisher nicht überzeugend umsetzbar.
- Begrenzte Kreativität: Thema Improvisieren und Feedback geben: KI Stimmen zu coachen ist bisher noch nicht möglich.
- Klang: Klar, KI Stimmen werden immer besser. Aber wer genau hinhört, kann KI Stimmen immer noch von echten Stimmen unterscheiden.
- Fehleranfälligkeit (nur bei Voice Cloning und GAN): Fehler, die die “geklonte” Zielperson z.B. in der Aussprache macht, werden auch von der Maschine übernommen
- Authentizität: Geklonte Stimmen sind nur gut, wenn sie mit einer großen Anzahl von Daten trainiert werden.
- Stabilität des Trainings: Das Training von GANs kann instabil sein und erfordert oft viel Erfahrung und Feinabstimmung.
- Fehlen von Kontrolle: GANs können unvorhersehbare Ergebnisse erzeugen, was die Kontrolle über die Sprachausgabe erschwert.
- Modus Kollaps (GAN): Der Generator kann sich auf die Generierung eines bestimmten Datentyps „festfahren“ und so die Vielfalt der erzeugten Daten einschränken.
- Ethische Bedenken: Nicht nur Jobs sind dadurch gefährdet. Auch bietet diese Technologie viel Spielraum für Kriminelle (Stichwort: Deepfakes)
Was sind die Vor- und Nachteile von Profisprechern?
Vorteile von Profi-Sprechern
- Natürlichkeit: Profisprecher haben eine natürliche Sprechweise und Artikulation, die KI-Stimmen oft fehlt.
- Emotionalität: Profisprecher können Emotionen und Nuancen in ihrer Stimme besser vermitteln als KI-Stimmen.
- Spontanität: Profisprecher haben viel Erfahrung im Sprechen vor Publikum und können sich daher besser an verschiedene Situationen anpassen.
- Identität: Manche Stimmen sind eng mit Marken verknüpft und wie ein Logo untrennbar mit der Marke oder dem Produkt verbunden. Siehe IKEA oder Praktiker.
- Coaching: Profisprecher können ihre Stimme gezielt einsetzen, um bestimmte Effekte zu erzielen.
- Feedback: Professionelle Voice Over Artists geben während der Aufnahme professionelles Feedback über z.B. Text- und Schreibstil bzw. die benötigte Geschwindigkeit oder evtl. Änderungen in der Wortwahl.
- Dialektik: Profisprecher können Dialekt oder Akzent sprechen.
- Flexibilität: Echte Voice Artists können sich an verschiedene Textsorten und Genres anpassen.
- Kreativität: Sprecher können eigene Ideen und Interpretationen in ihre Arbeit einbringen. Sie können improvisieren und spontan auf neue Situationen reagieren.
Nachteile von Profi-Sprechern
- Preis: Ein professioneller Synchronsprecher kostet Geld. Und je besser und bekannter eine Stimme ist, umso teurer ist sie auch.
- Buchung: Beliebte Sprecher sind oft ausgebucht, man muss u.U. lange auf einen Aufnahme Termin warten.
- Inkonsistenz: Die menschliche Stimme ist anfällig für Veränderungen, wenn auch meist nur subtil (Krankheit, Unfall)
- Technik: Eine professionelle Sprachaufnahme benötigt professionelle Technik. Diese muss bedient werden können und kostet Geld.
- Sprachenvielfalt: Professionelle Sprecher sprechen in der Regel nur eine oder wenige Sprachen, bzw. Dialekte.
Sprecher vs KI-Stimme: Fazit
Kommen wir nun zu der alles entscheidenden Frage: Lohnt es sich noch, professionelle Synchronsprecher zu buchen, oder können Maschinen den Job nicht genauso gut oder besser erledigen? Ist die Büchse der Pandora schon geöffnet?
Wie wir gesehen haben, haben beide beschriebenen Sprech-“Systeme”, also Mensch und Maschine ihre Vor- und Nachteile. Eine einzige, allgemeingültige Antwort gibt es also nicht. Wie in so vielen anderen Bereichen auch, stellt sich bei der Auswahl einer Stimme für die Kommunikation die Frage nach dem Zweck und der gewünschten Rezeption. Und nicht zuletzt auch nach dem Budget. Meiner Ansicht nach sollte man sich daher aus professioneller Sicht immer zuerst darüber klar werden, welches Produkt man vertonen möchte.
Geht es zum Beispiel um ein E-Learning oder journalistische Inhalte (Stichwort reine Informationsvermittlung)? In diesem Falle könnten die Vorteile einer künstlich erzeugten Stimme überwiegen. Zu diesen zählen hier z.B. die höhere Geschwindigkeit, in der neue Inhalte vertont werden können oder die unbeschränkte Verfügbarkeit der künstlichen Stimme, sowie die Option, die Inhalte sofort in unzähligen Sprachen zu produzieren.
Ähnliches gilt für die Produktion von Werbespots: Gerade kleinere Firmen mit weniger Budget profitieren von günstigen künstlichen Stimmen, die sich nicht verändern, überall verfügbar sind und hunderte Sprachen beherrschen. Allerdings müssen hier natürlich im Zweifel bei der Qualität Abstriche gemacht werden.
KI kann keine Kunst
Bei einem Hörbuch oder Hörspiel sieht das Ganze natürlich wieder etwas anders aus. Hier überwiegen meiner Ansicht nach die Vorteile echter Voice Artists. Dazu gehören natürlich Spontanität und Feedback zum Text, Dialekt-Fähigkeit, Empathie und Kreativität. Nicht zuletzt muss ein Sprecher den zu interpretierenden Text zuerst verstehen (!) Ein nicht zu unterschätzender Aspekt.
Dazu hier ein Zitat aus dem Buch “Sprachverarbeitung: Grundlagen und Methoden der Sprachsynthese und Spracherkennung (2017)”:
„Ein ideales Sprachsynthesesystem soll selbstverständlich beide Fehlerarten vermeiden. Das heisst, dass es den Text verstehen muss, wie dies auch bei der vorlesenden Person erforderlich ist. Das Vorlesen ist deshalb sehr schwierig maschinell nachzubilden.” (vgl. Pfister/Kaufmann, S.194)
Wie wir schon in der Einleitung bemerkt haben, leben wir schon seit längerem mit künstlich erzeugten Stimmen. Die Rezeption der Konsumenten ist nicht durchweg schlecht und hängt natürlich immer mit dem eigenen Anspruch sowie der Intention des Produktes zusammen. Bei einigen Produkten wird sich daher in Zukunft der Einsatz geklonter Stimmen lohnen, bei anderen nicht4. Daher habe ich weiter oben auch meine eigene Definition des „Sprecher“-Begriffs erweitert. Mensch und Maschine werden, wie in vielen anderen Bereichen des Lebens auch, lernen müssen, miteinander zu leben.
Wie also schon bei Epimetheus und Pandora: Wir können und werden uns arrangieren (müssen). Es liegt an uns, was wir aus der Situation machen. Ich persönlich denke und hoffe nicht, dass der Sprecherberuf aussterben wird. Ein Teil des Marktes wird in Zukunft sicherlich von KI-Stimmen übernommen oder durch sie ergänzt, aber der restliche Teil wird evtl. sogar eine Aufwertung bekommen – Da nun endlich klar wird, wie viel Arbeit und Wert in der Kunst und dem Handwerk des Sprechens steckt.
Eine große Problemstellung für synthetische Stimmen wird auf absehbare Zeit vor allem die Zusammenarbeit und die Fähigkeit, Briefing umzusetzen sein. Das sehe ich als Tonmeister noch nicht umsetzbar. Ausserdem wird der künstlerische Bereich, sprich Charakterstimmen, Hörbücher etc. sehr wahrscheinlich weiterhin fest in menschlicher Hand bleiben. Was die Synchron-Arbeit angeht bleibt jedoch abzuwarten5 .
Was wir von KI Stimmen halten
Abschliessend möchte ich noch hinzufügen, dass wir bei Vellocet Audio nach wie vor ausschliesslich mit echten, professionellen Sprechern und Sprecherinnen arbeiten. Wir haben keine KI-Stimmen im Angebot und haben auch nicht vor, dies in naher Zukunft zu tun. Unsere eigene, handkuratierte In-House Sprecherdatenbank wächst und gedeiht.
Die ganze Entwicklung, bzw. der technische Stand von künstlichen Stimmen kam für uns nicht sonderlich überraschend, da wir schon seit vielen Jahren in der Branche arbeiten und das Thema KI im Audio Engineering schon länger eine Rolle spielt. Der Sprung zu „KI-Stimmen“ war daher nicht sonderlich weit. Wir sind allerdings keine sonderlich großen Fans von KI-Stimmen – Ihnen fehlt einfach das entscheidende Quäntchen: Menschlichkeit. Und das wird unserer Meinung nach auch so bleiben.
Falls Euch dieser Artikel gefallen hat, leitet ihn gerne weiter. Weiter unten findet ihr auch eine Kommentarsektion. Lasst mich gerne wissen, was ihr über das Thema KI-Stimmen denkt.
- https://api.semanticscholar.org/CorpusID:122512841 ↩︎
- https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=dcb1aefcc8d80c90392fa9b6f2740b4516e8ec44 ↩︎
- https://ieeexplore.ieee.org/document/8462018 ↩︎
- https://omr.com/de/daily/synthetische-stimmen-ki ↩︎
- https://www.handelsblatt.com/technik/it-internet/deepdub-wie-eine-ki-die-arbeit-von-synchronsprechern-uebernimmt/29252038.html ↩︎
Kommentar verfassen